aws ec2가 어떻게 baremetal performance를 내는걸까
틀린 내용이 있을 수 있습니다. 정정해주시는 코멘트를 남겨주신다면 감사하겠습니다.
Hypervisor
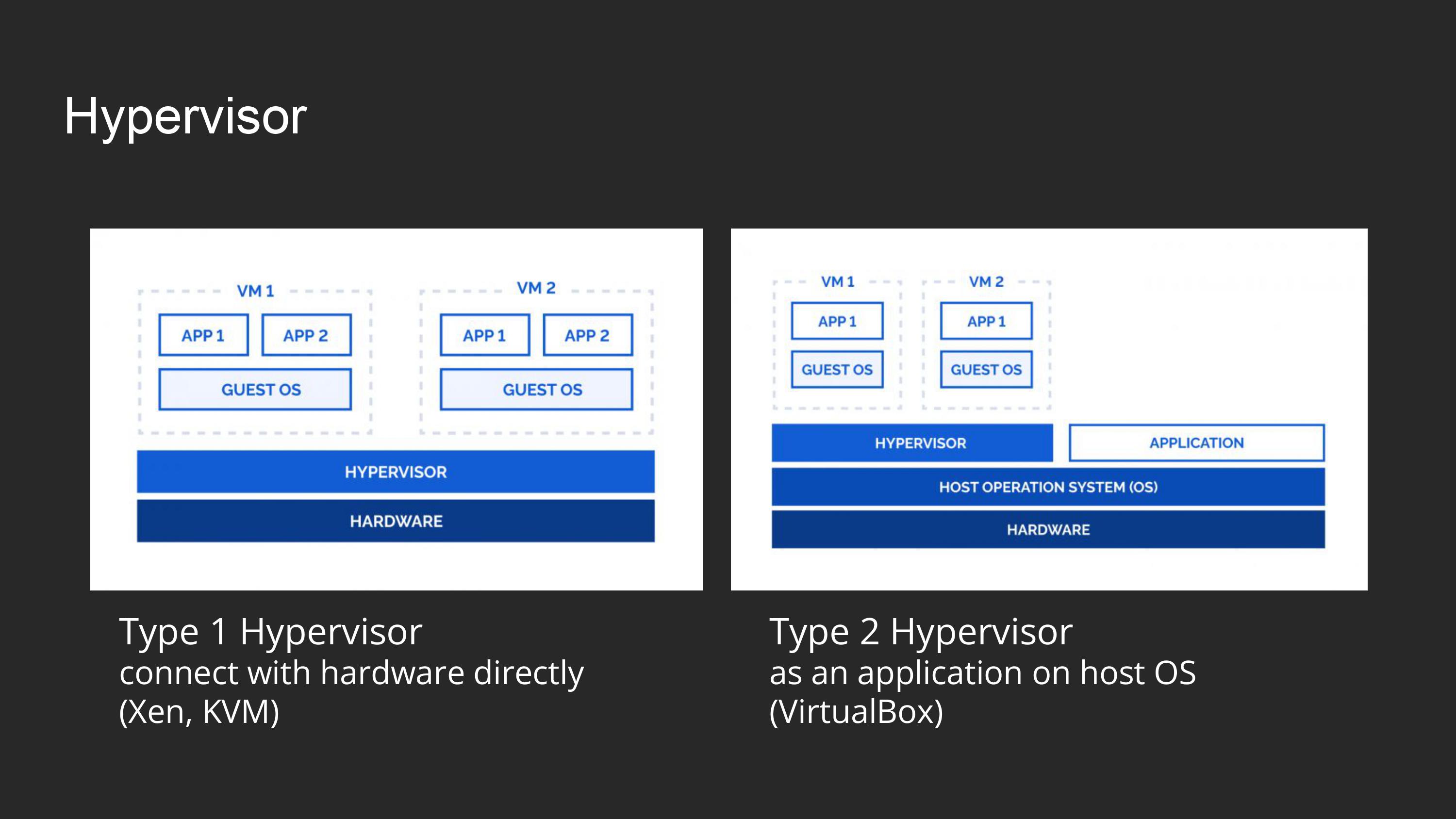
Hypervisors: Type 1 vs Type 2. [PART 1]
- Type 1 Hypervisor
- Host OS 없이 동작하는 hypervisor
- 이 글에서 나오는 Hypervisor는 Type 1임
- Type 2 Hypervisor
- VirtualBox 같이 Host OS위에서 애플리케이션으로 돌아가는 hypervisor
Virtualization
https://youtu.be/LabltEXk0VQ?t=252
Virtualization이란 무엇인가? 갑자기 instruction level로 가보자.. (슬라이드에서 instruction을 이해할 필요는 없습니다)
어떤 명령(instruction)은 그냥 실행이 가능한 반면, 어떤 명령은 불가능하다.
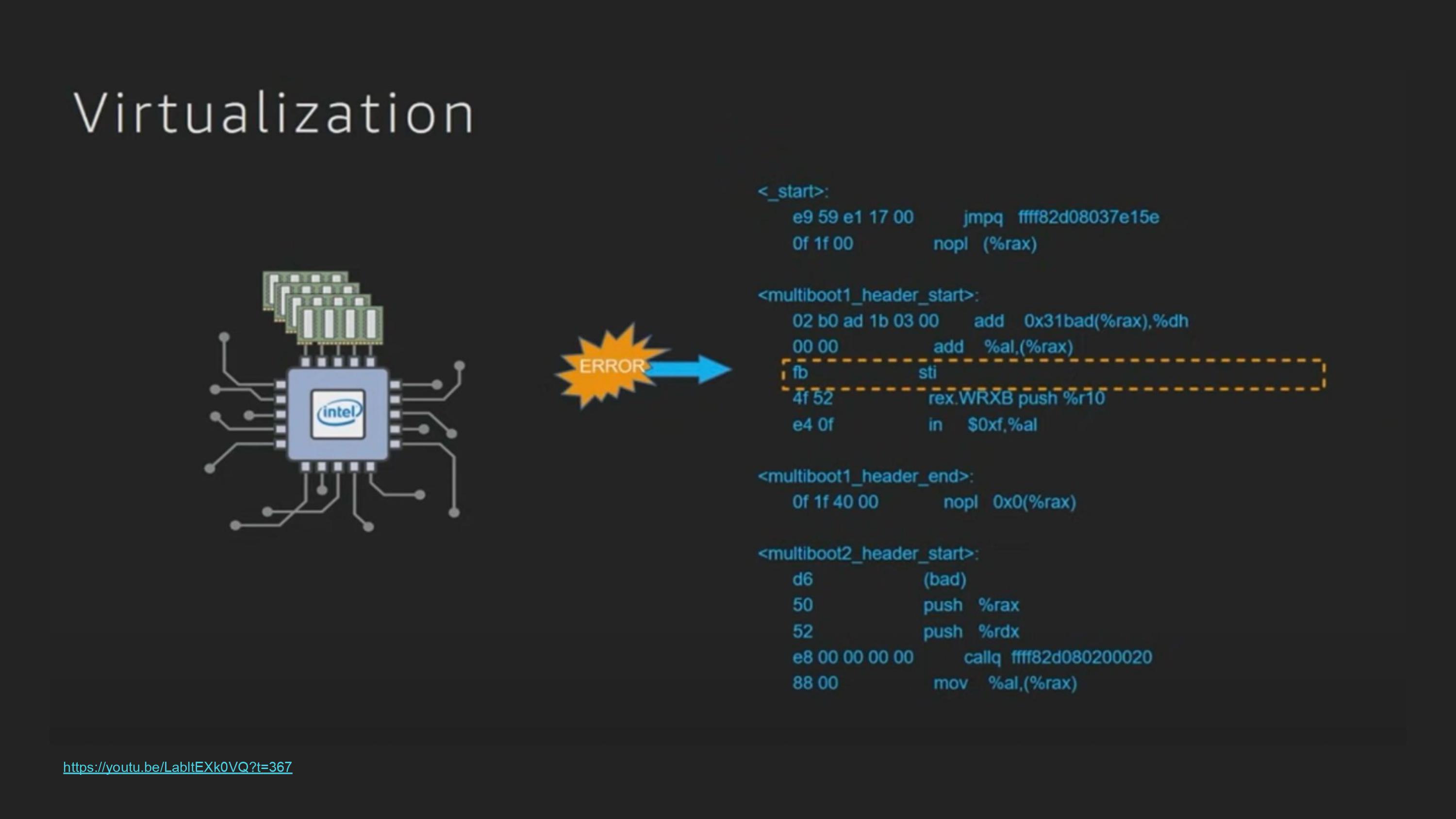
sti instruction은 process 스스로 실행이 불가능함.
linux application으로 virtualization 없이 이런 instruction을 실행한다면 crash가 발생하게될 것
이런 instruction을 privileged instruction이라고 함
모든 processor들은 multiple privileged level을 가짐
Virtualizable 조건중 하나: unprivileged mode에서 privileged instruction을 수행할때 trap이 발생해야 한다.
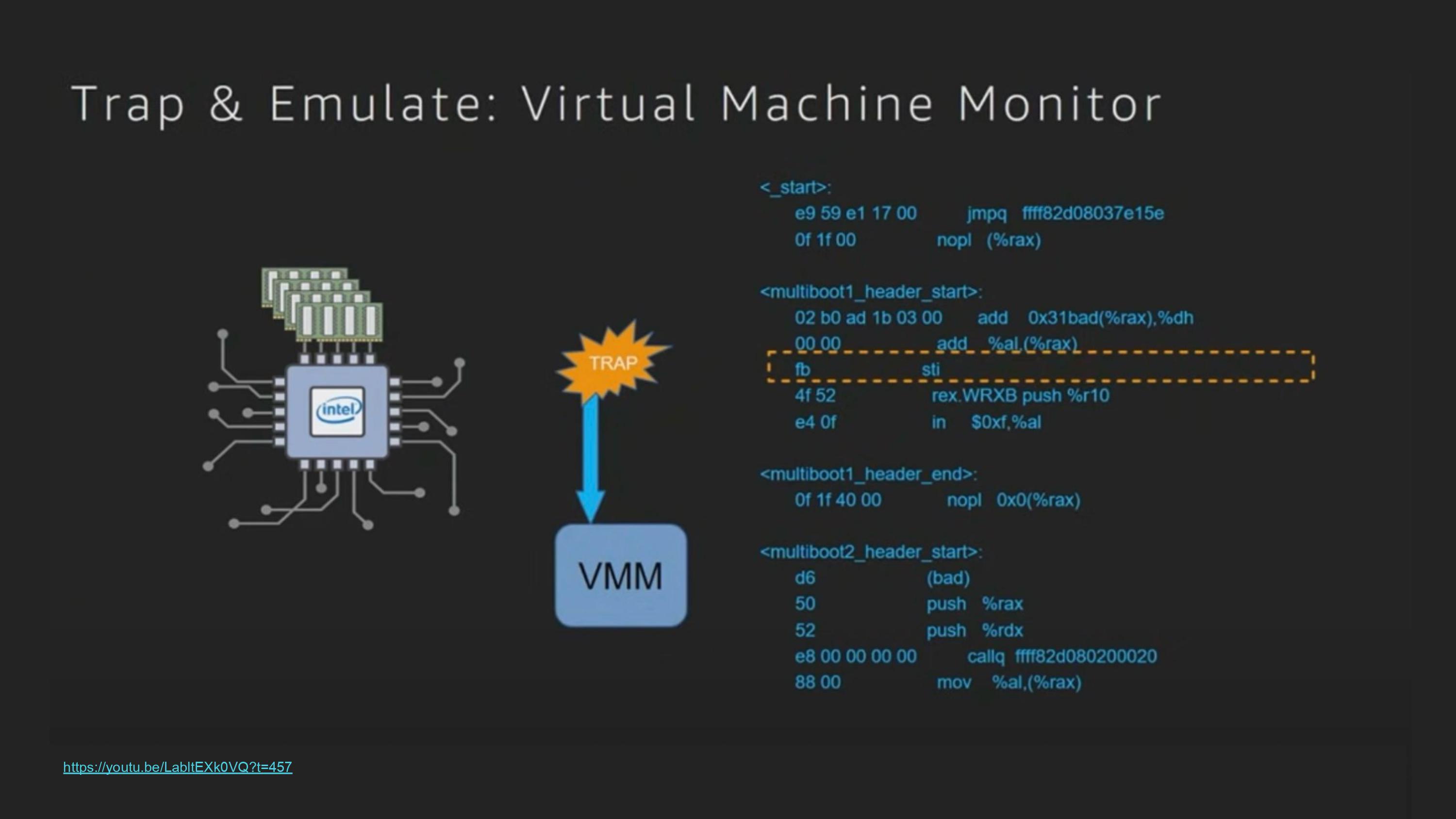
sti 같은 instruction을 unprivileged mode에서 실행한다면 error를 발생시키고 이 instruction을 VMM(Virtual Machine Monitor)에게 전달.
VMM은 instruction을 받아 emulate해줌
sti는 특정 register 하나를 변경하고 결과를 stack push함- VMM은 이 역할을 가짜로 수행해서 stack push함

Virtualization의 요구사항
- 대다수의 instruction이 native(unprivileged)로 동작해야한다.
- modern hypervisor는 10억개중에 1개정도의 instruction만이 emulate됨
하지만 VM은 대부분을 처리하지만, 모든걸 처리해주진 못함. 어떤 hardware와 엮여있느냐에 따라서도 달라짐

Hypervisor는 VMM과 device model(device를 emulate하거나, 연결하는데 사용)들, scheduler, memory manager, logging등으로 구성됨
hypervisor의 성능을 올리기 위해, 수행하는 대부분의 작업은 device model에 존재하며, 이게 hypervisor를 복잡하게 만듦.

https://youtu.be/LabltEXk0VQ?t=764
EC2가 처음 출시된 2006년, 70년대부터 존재한 virtualization이었지만, 당시 intel/amd processor들은 trap을 잘 처리하지 못했음.
HW가 trap을 효율적으로 처리하지 못하니 virtualization이 인기가 없어 지원하지 않았던것임.
하지만 Xen에서 이 문제를 다른 방식으로 해결했는데, guest OS를 수정해서 trap을 수행하는 대신 직접 VMM을 호출하도록 변경 (Paravirtualization)

Xen and the art of virtualization (SOSP '03)
Full virtualization
- guest OS를 수정하지 않고 trap이 발생하면 해당 instruction을 보고 필요한 행동을 수행, 성능이 저하되는 원인
Paravitualization (Xen)
- guest OS를 수정해서 Full virtualization에서 수행하던 translation을 제거 -> 오버헤드 감소
- Dom0라 불리는 special guest OS만이 device와 직접 통신하고, 다른 guest OS들은 device호출을 Dom0에게 요청하는 형태
- hypervisor가 L0의 privileged level을 가지고, guest OS는 L1, user application은 L3
Toward Nitro System

https://youtu.be/LabltEXk0VQ?t=905
2012년 AWS의 고민
- software로만 동작하는 (Xen) Hypervisor보다 더 좋은 성능을 낼 방법 필요
- Hypervisor는 guest OS와 CPU/memory usage를 공유하고 있는 상황, 성능 모두를 guest OS가 쓰게 해줄 수 없음
- (당시) 대부분의 hypervisor는 hw agnostic이지만, AWS는 datacenter를 가지고 있으므로 수직 최적화가 가능함
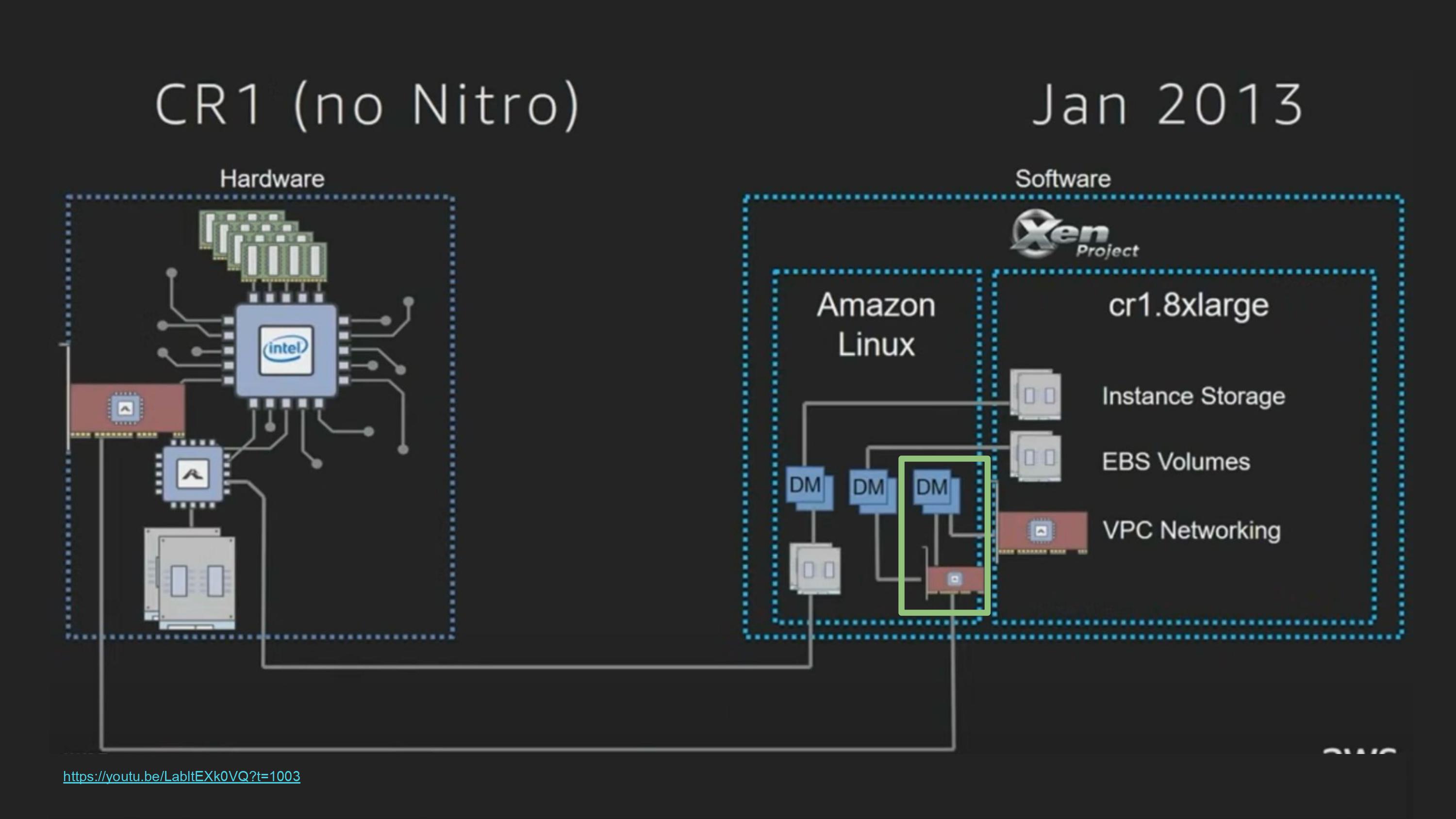
https://youtu.be/LabltEXk0VQ?t=1003
Nitro가 없던 시절 인스턴스
Xen을 사용하고 있었으므로, dom0역할을 하는 OS내에 storage, EBS, network에 해당하는 Device model 존재
따라서 모든 device 요청은 dom0를 통해 수행되며, 이때마다 user instance (guest OS)와 리소스를 두고 경쟁할수밖에없음
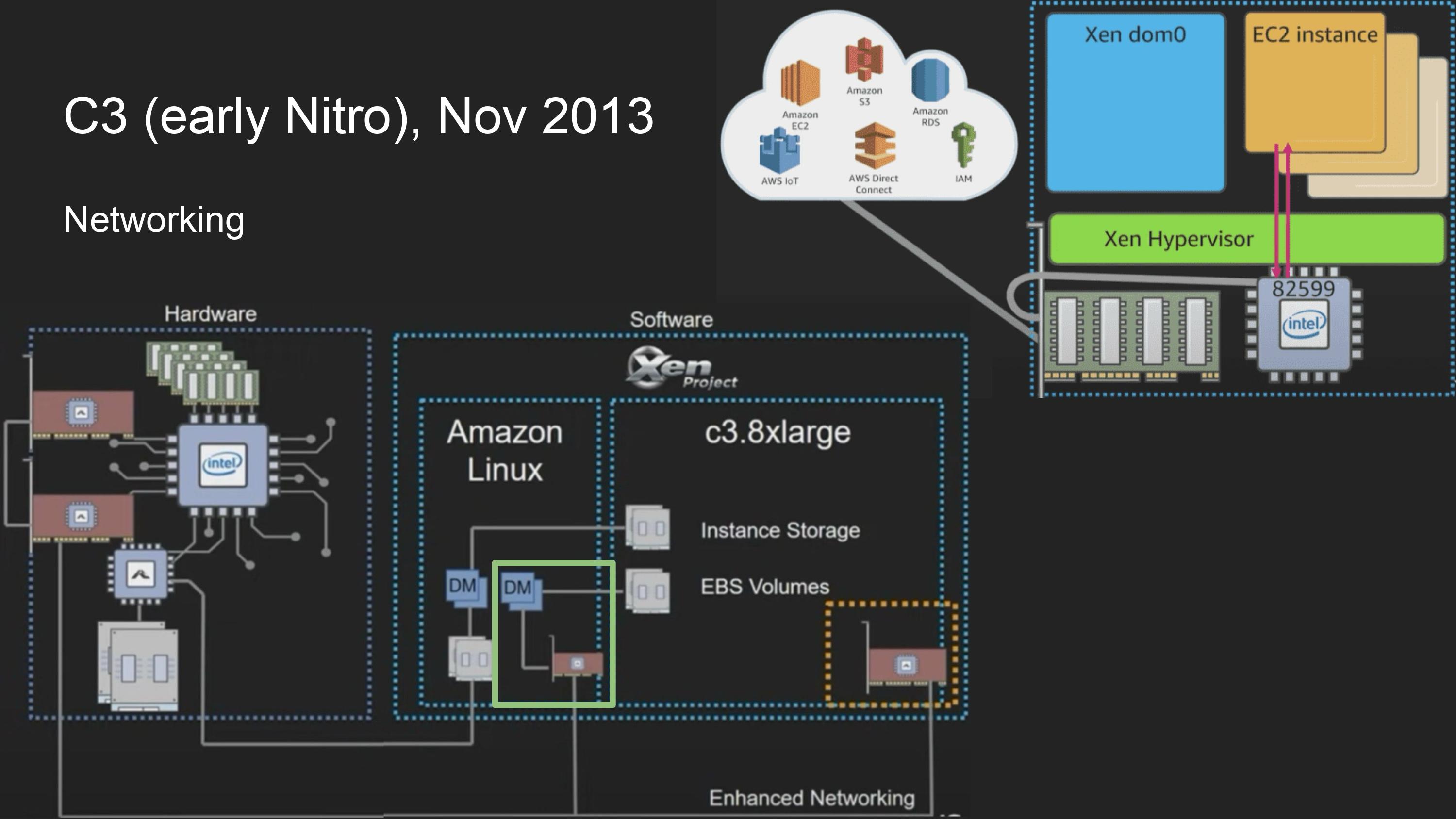
network를 HW로 offloading한 첫 인스턴스
당시 시장에 나와있는 network card로 network processing, VPC를 offloading 할 수 있었음.
하지만 SR-IOV(Single Root IO Virtualization)를 지원하는 card는 없었는데, 이는 PCIe device를 가상으로 노출시켜주는 기능임. network card를 한개 꽂고 멀리 있는 storage를 EBS로 노출시킨다거나 하는데 필요함
이를 해결하기 위해 intel 82599 chip을 nitro card와 연결했고, network device model을 guest os가 직접 접근할 수 있도록 수정
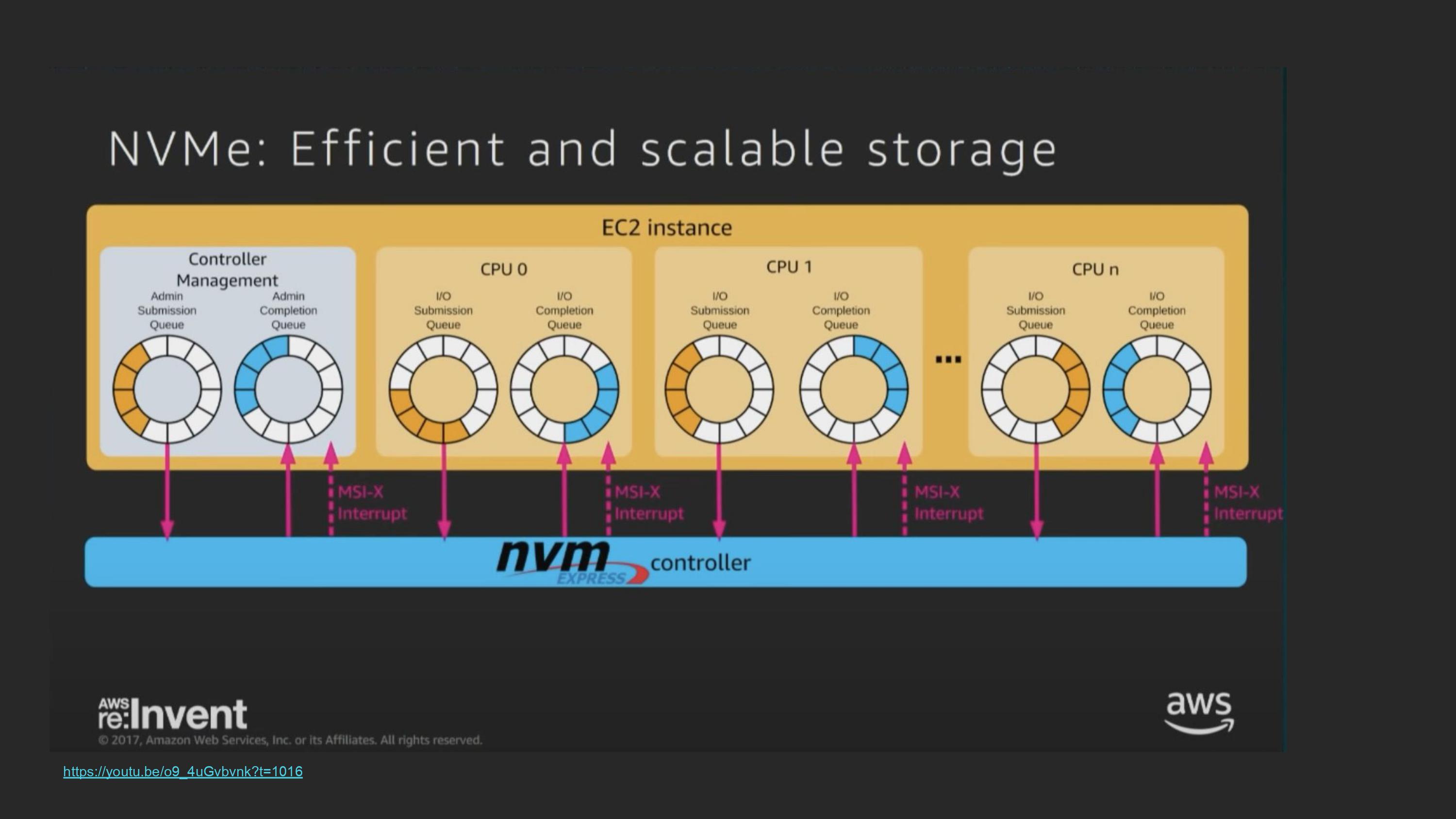
EBS offloading을 보여주기 위해 NVMe에 대한 간단한 소개.
NVMe는 PCIe에서 ssd를 연결하기 위해 만들어짐. 따라서 EBS offloading이 가능. cpu마다 dedicated submission/completion queue가 있어 각 cpu가 io를 직접할수있음
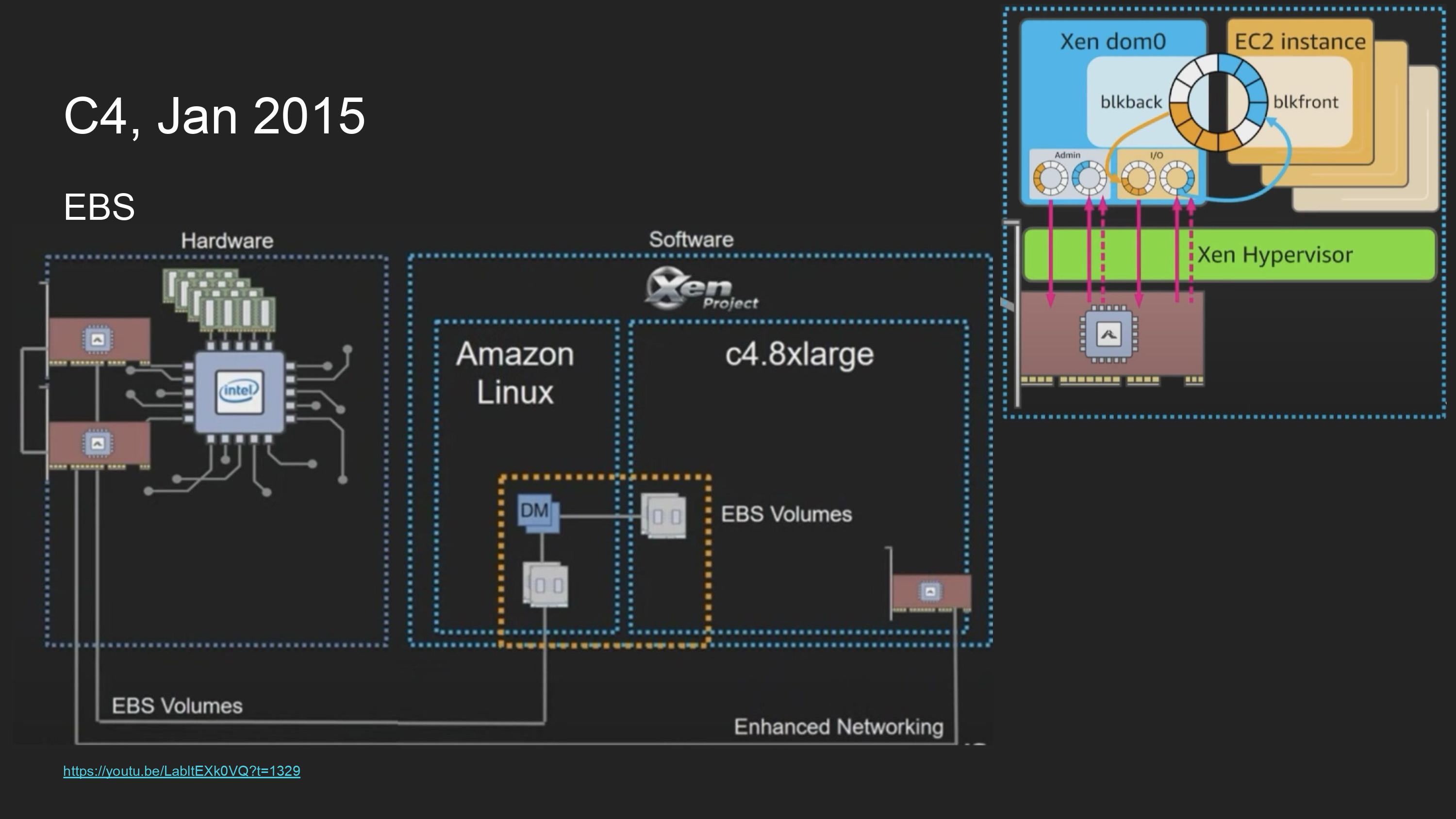
Nitro card에서 network interface로 NVMe를 지원하게 만들었음.
network와 달리 완전히 offloading하진 않고 Device model을 유지했는데, 당시 NVMe는 새 기술이었고 여러 guest OS에 적용하기엔 시기상조였으므로 호환성을 위해서 Device model을 유지함
하지만 EBS를 guest OS가 쓰기 위해서 dom0가 ebs를 관리하던것들은 모두 nitro card로 offloading 되었음
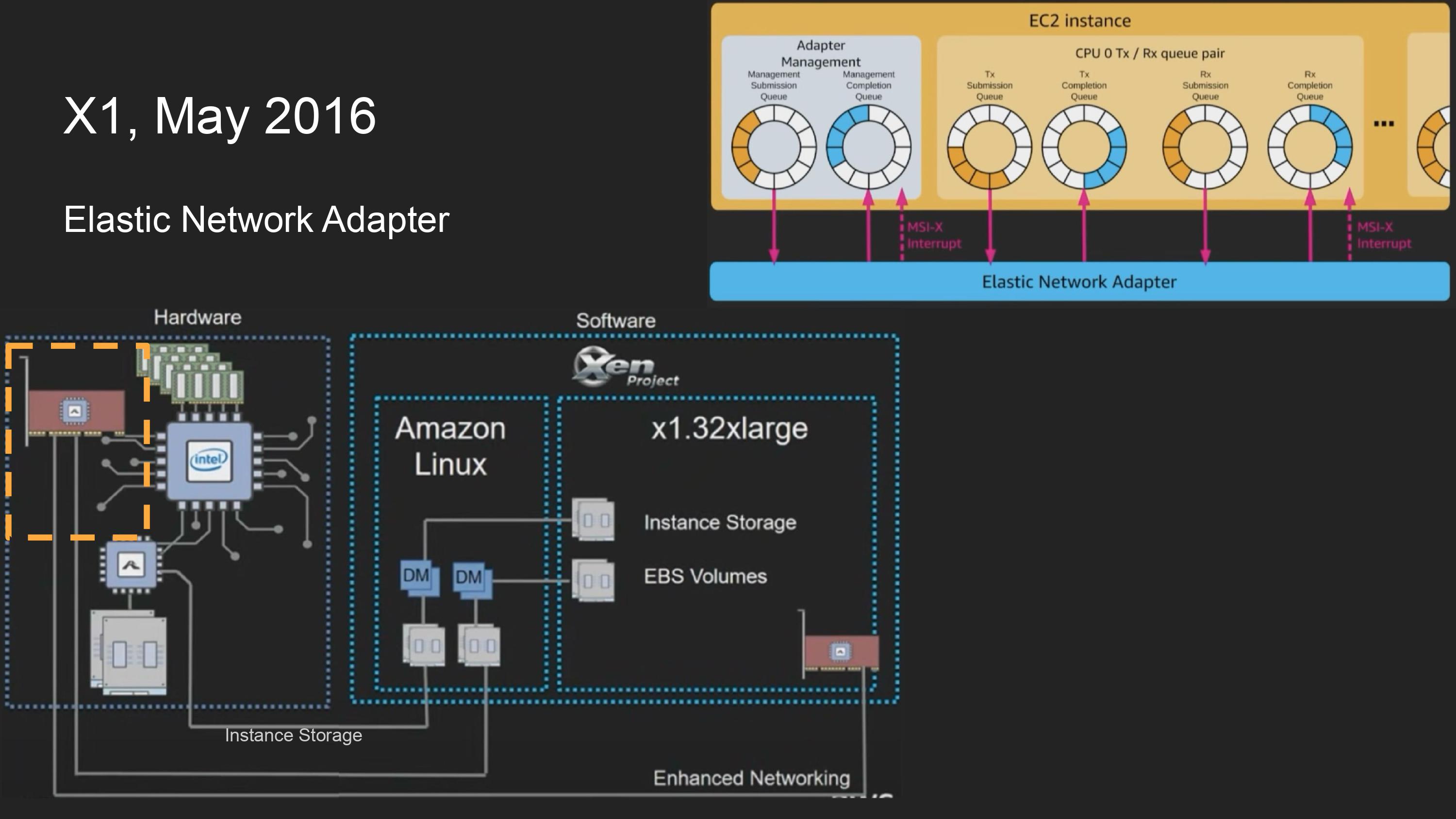
ENA(Elastic Network Adapter) 도입과 함께 완전한 nitro card 를 도입.
이전세대의 nitro card는 SR-IOV를 위해 intel 82599 chip을 필요로 했으나, 이 chip은 10gbps만 지원하므로 bandwidth에 한계가 있었음.
Nitro card에서 NVMe의 컨셉을 따라서 network를 지원하게 만들고, SR-IOV도 내장시켜 intel 82599 chip은 제거하여 25gbps까지 가능해짐
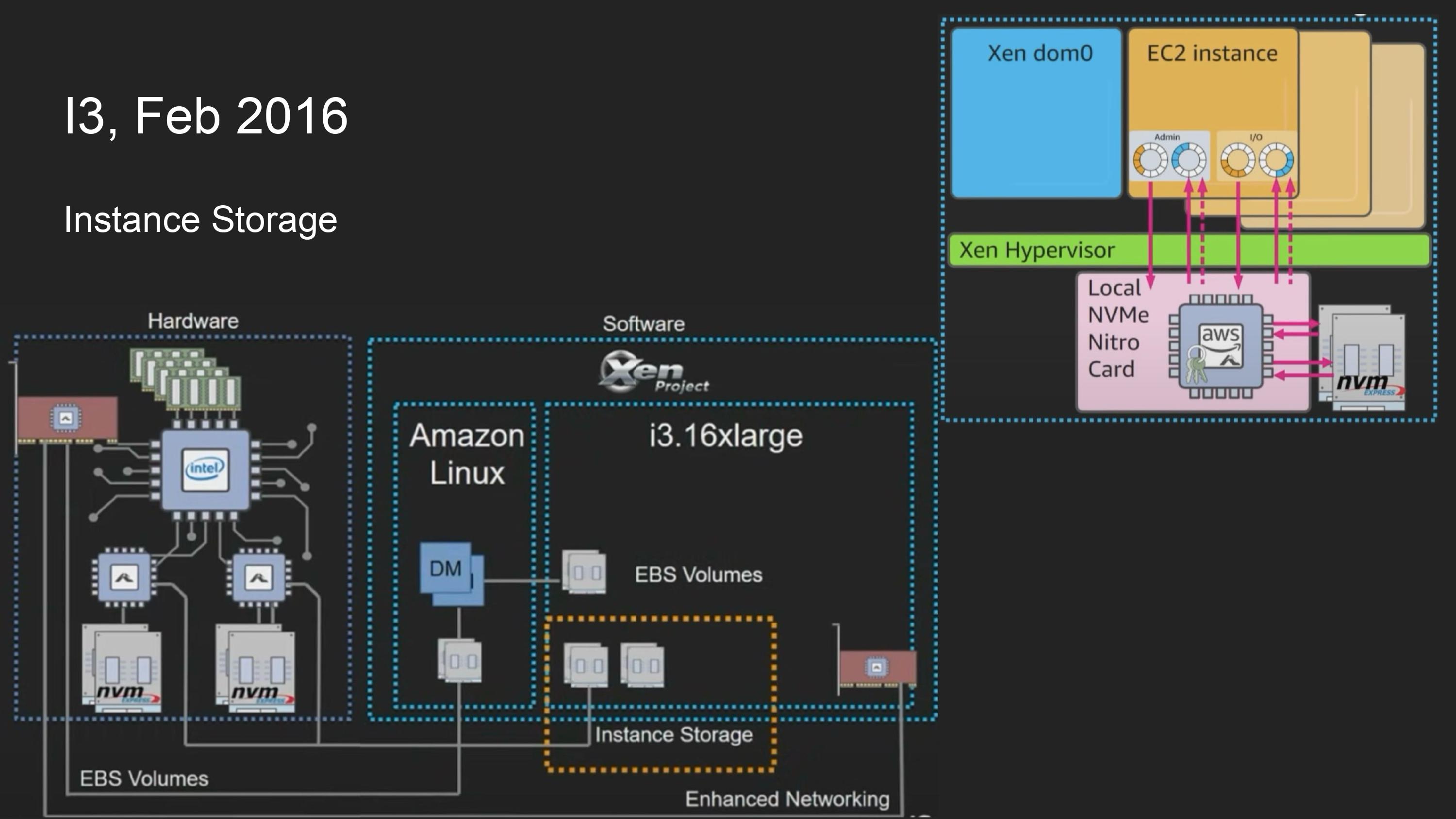
i3에선 (Local) instance storage offloading도 하였음.
nitro card가 ebs에서 쓰이던 암호화 연산을 하는것을 instance storage에서도 활용하고, dom0의 device model은 제거하며 guest OS가 직접 instance storage와 통신하게됨
https://youtu.be/eWFEJmsddV0?t=1259
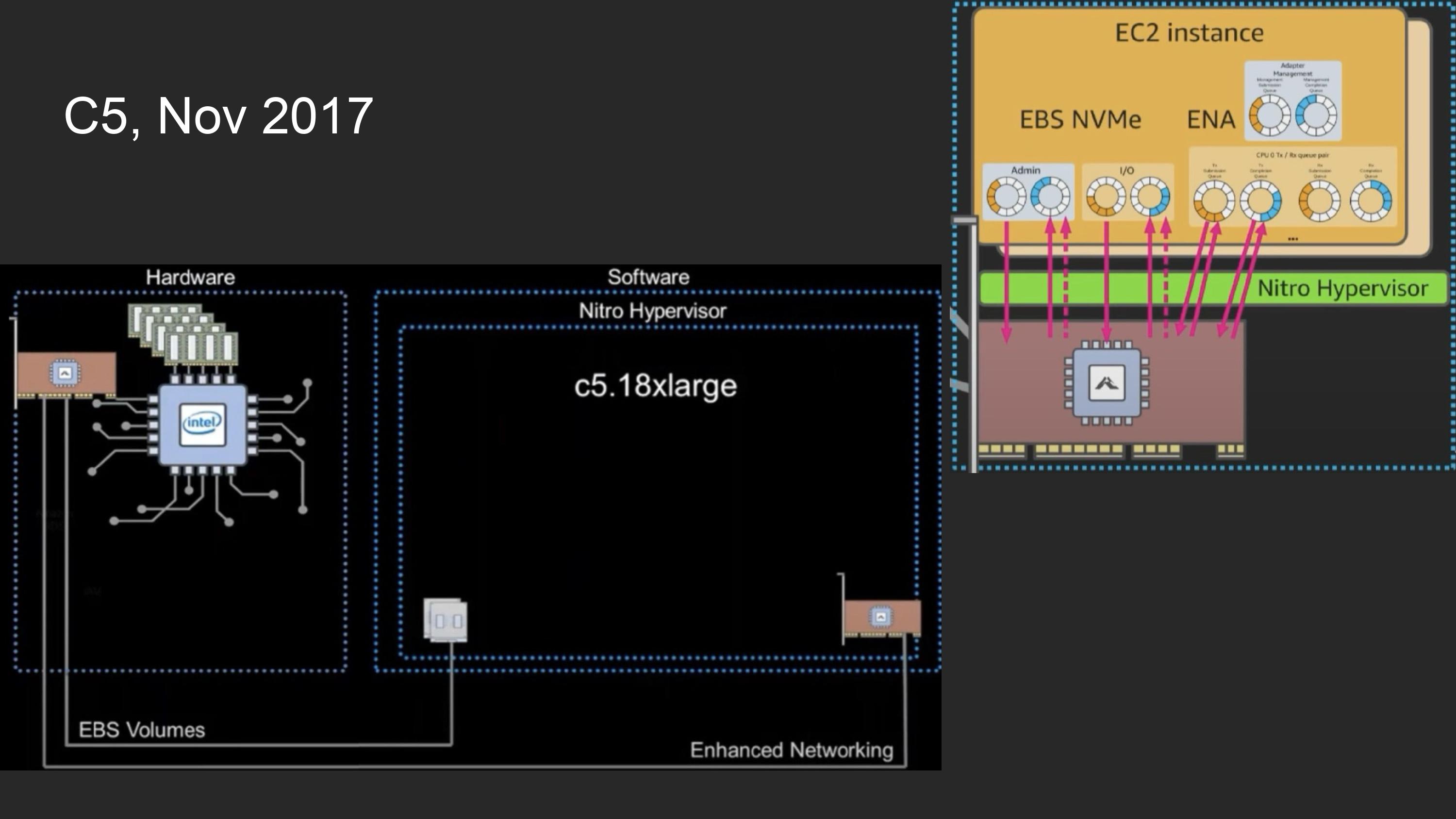
EBS device model을 제거 - NVMe에 시장에 안착된것과 여러 OS에서 지원하고있으므로
또한 device와 통신하기 위해서 존재하던 dom0가 제거되며, Xen Hypervisor도 오로지 VMM 역할만 하는 Nitro Hypervisor로 변경됨
따라서 Hypervisor가 device와 통신하는 부분을 software로 관리하던 모든 컴포넌트 (dom0)가 사라지고, nitro card로 offloading되어 baremetal에 가까운 성능을 낼 수 있게 됨
https://youtu.be/Cxie0FgLogg?t=362
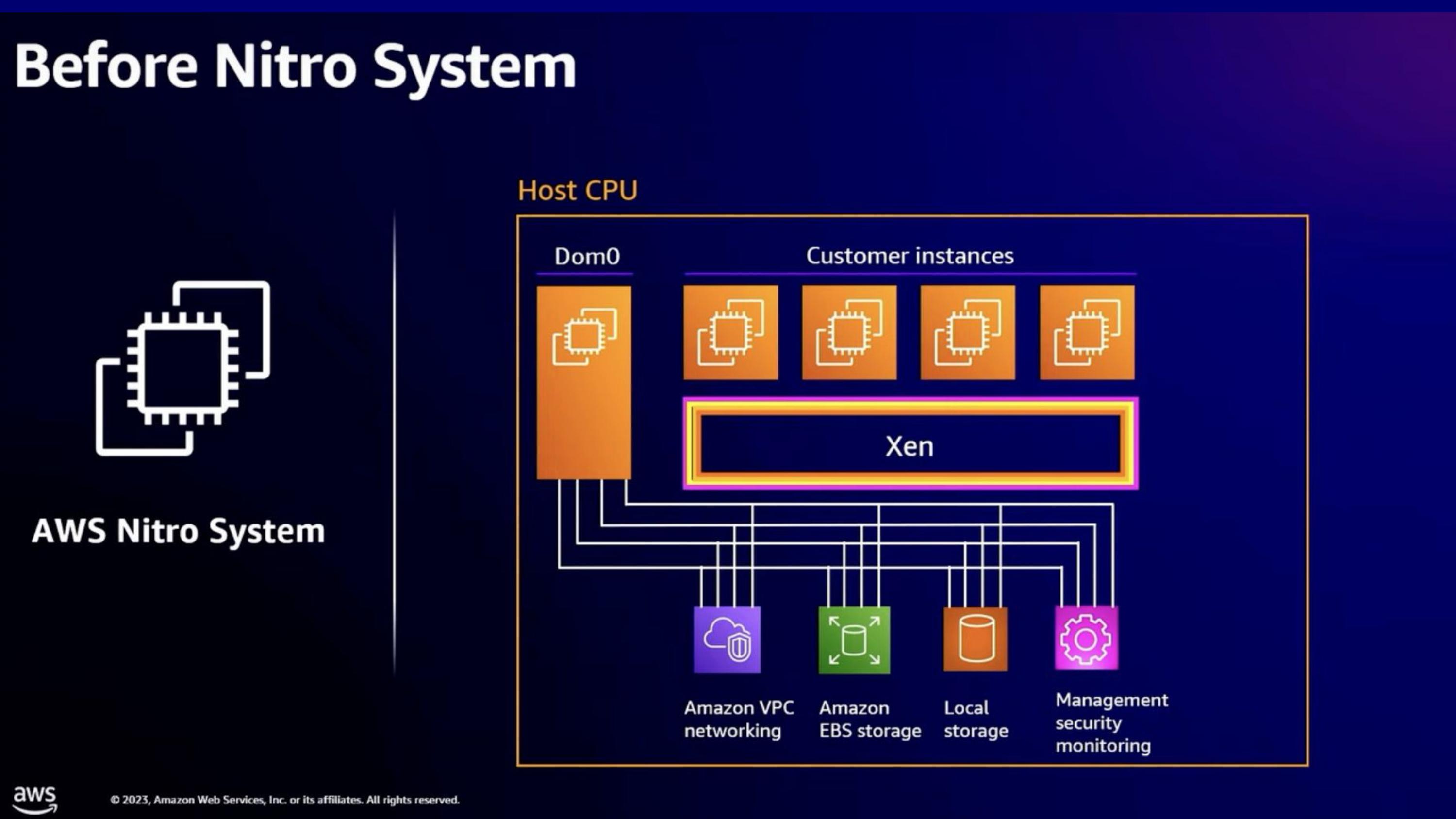
이전까지 나왔던 내용의 요약. Nitro 이전
- Xen 위에서 실행
- Dom0 VM이 디바이스와 통신을 담당
https://youtu.be/Cxie0FgLogg?t=362
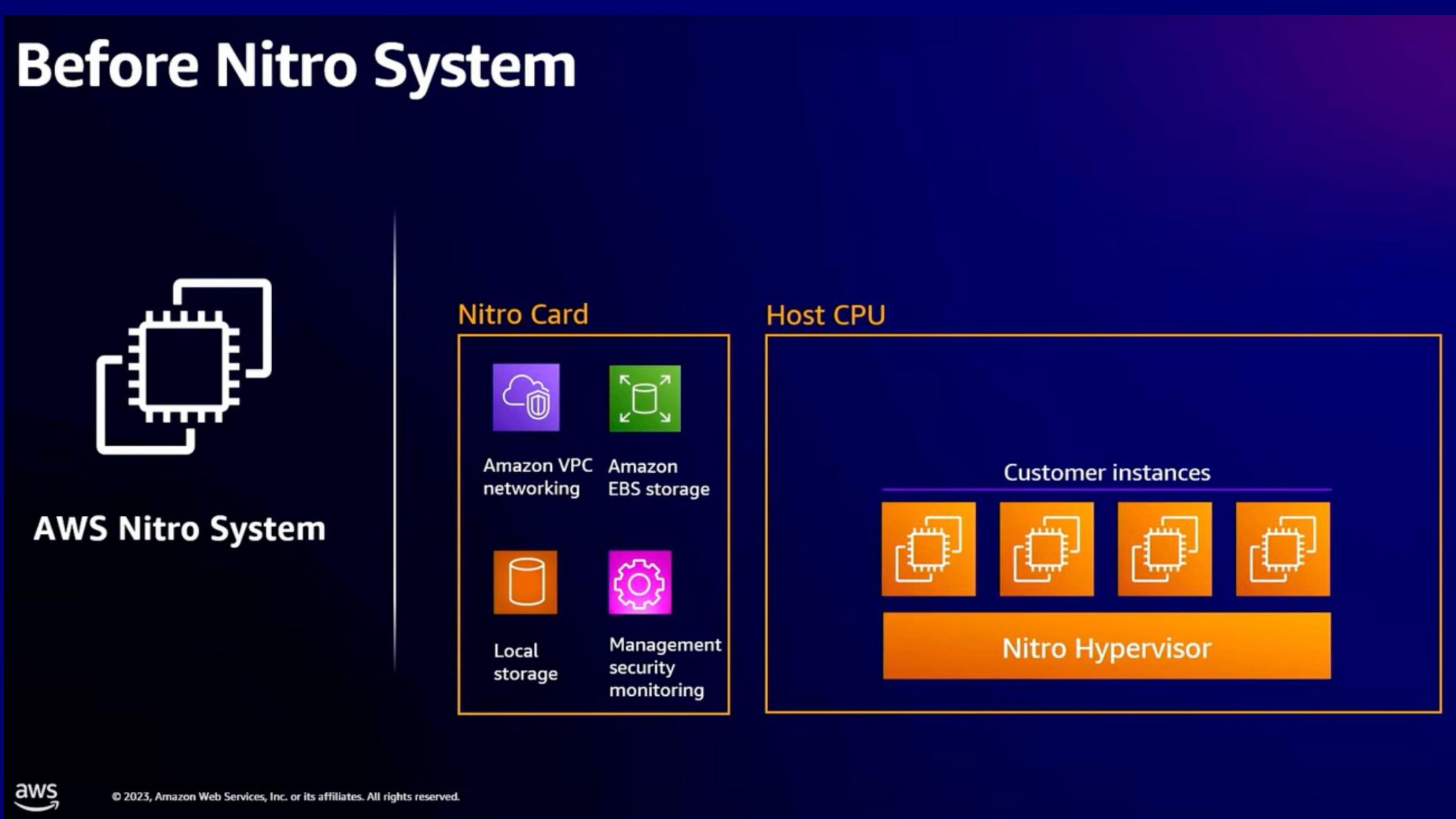
Nitro가 모두 도입된 그림
- Xen hypervisor는 사라지고 Nitro hypervisor (privileged instruction만 처리)
- Device model은 Nitro card로 offloading되었음
- User instance는 SR-IOV를 통해 Nitro card와 직접 통신
VPC Networking
https://youtu.be/Cxie0FgLogg?t=574
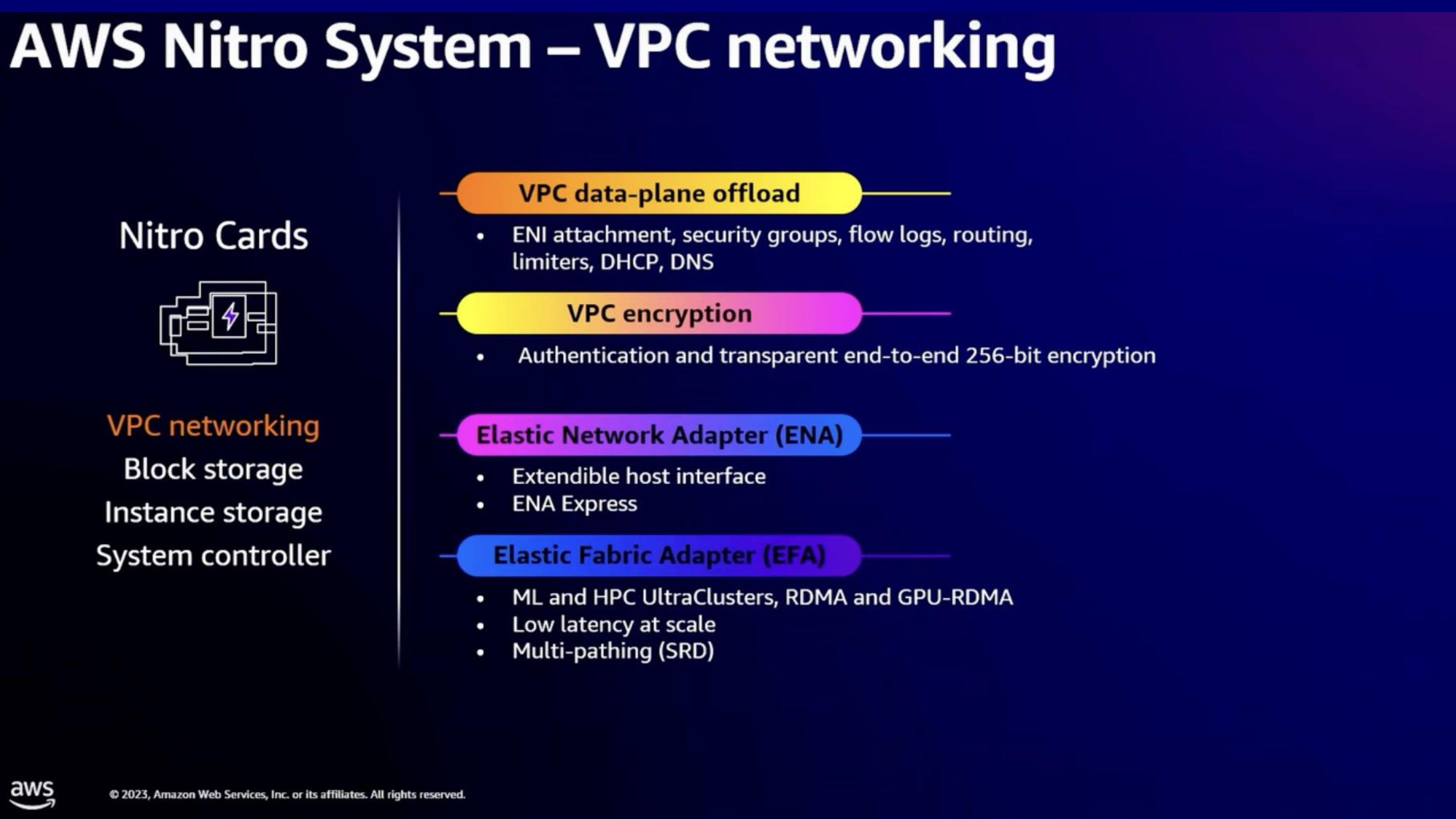
- Nitro card 에서 제공해주는 4개 기능중 하나인 VPC networking에 대한 소개
- 이중 ENA Express, EFA에 적용된 SRD를 봐보자.
SRD (Scalable Reliable Datagram)
https://youtu.be/Cxie0FgLogg?t=593
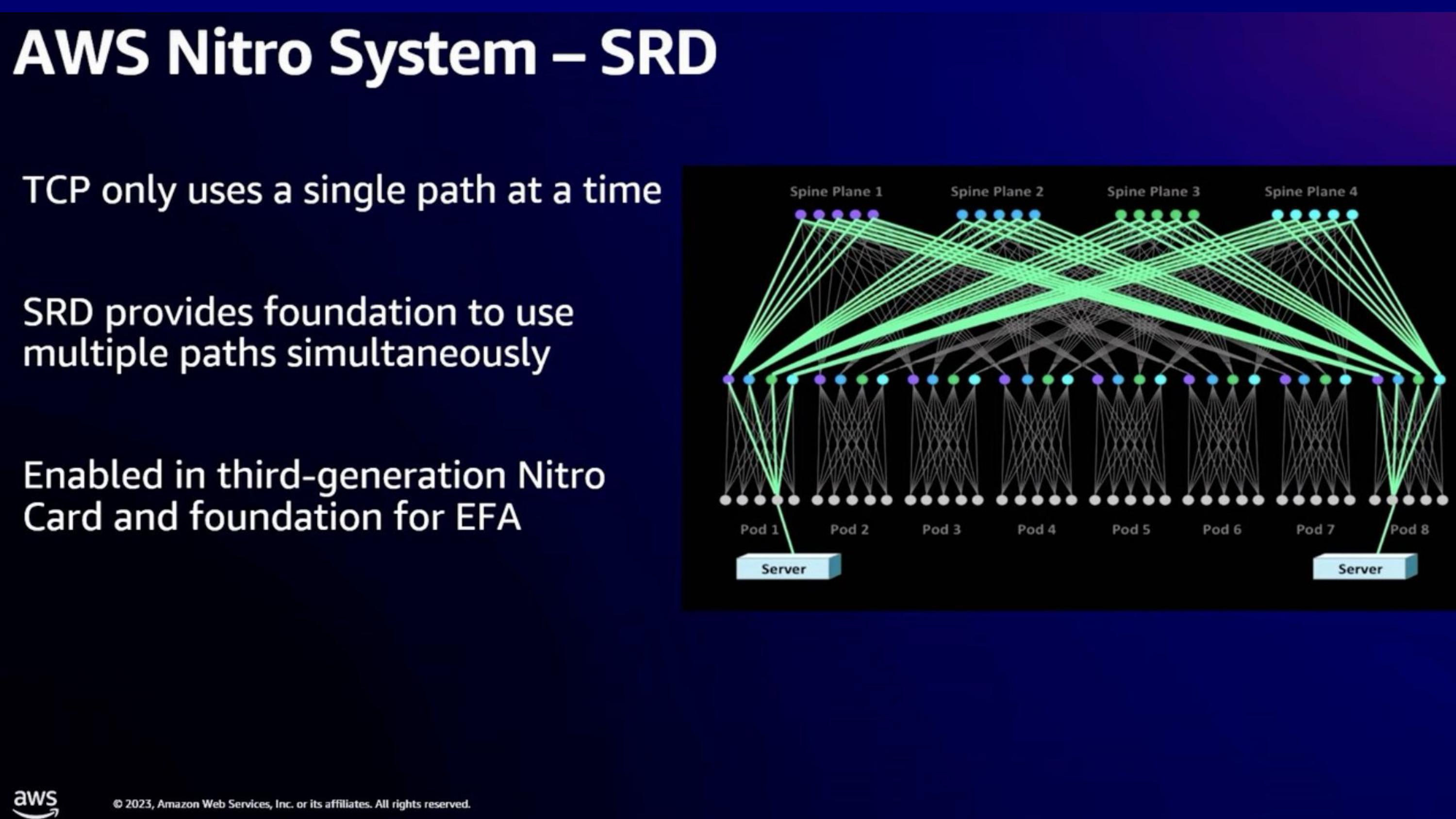
- TCP는 single path만 사용하지만 datacenter network는 multipath가 가능하다
- 또한 multipath라면 congestion에 대해 더 빠른 대응이 가능하다
- SRD가 multipath를 활용해서 패킷을 전달
- HPC workload의 경우 P50 latency가 괜찮더라도, tail latency가 느리다면 전체적으로 느려진다
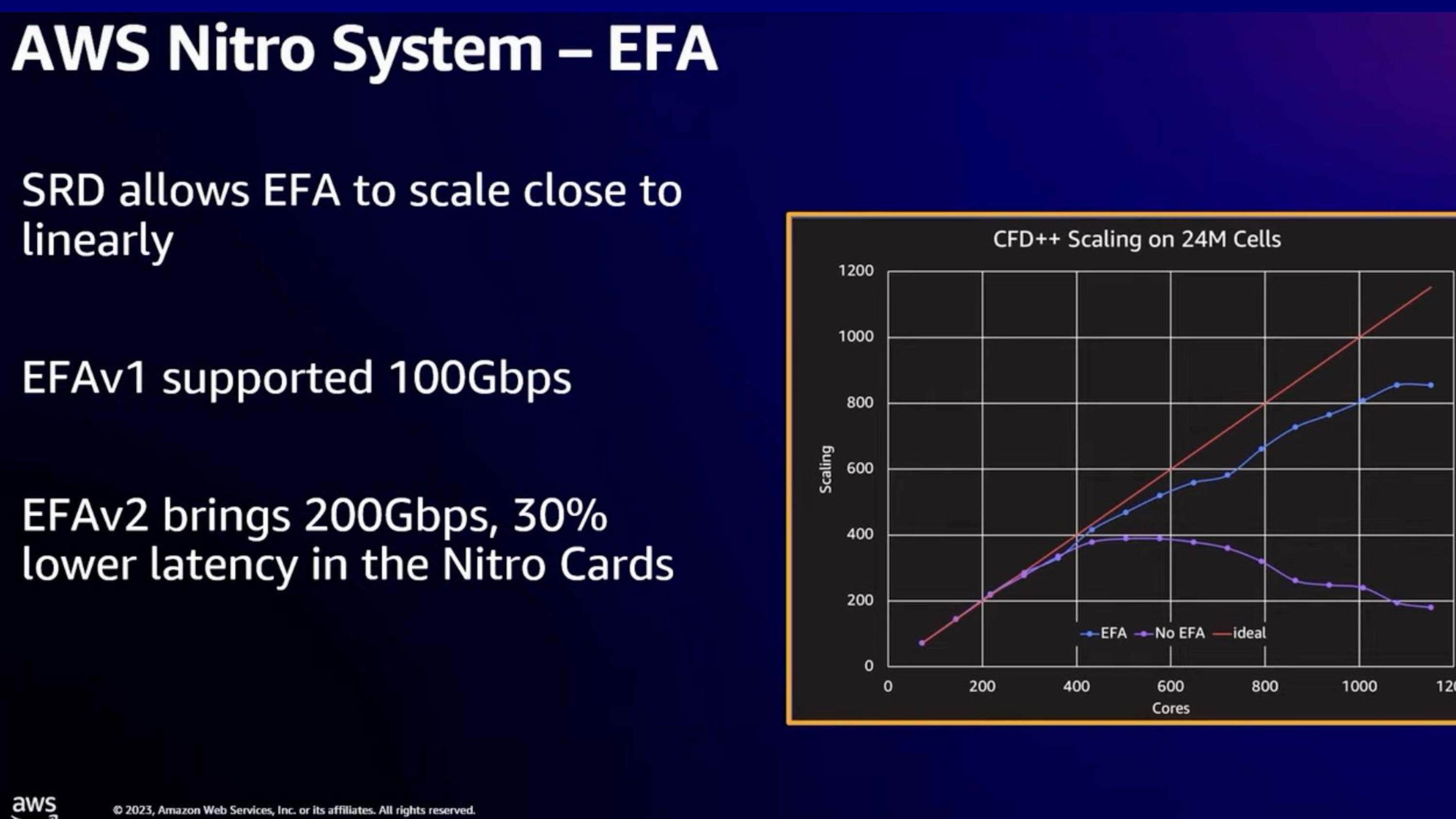
https://youtu.be/Cxie0FgLogg?t=660
- SRD를 적용했을때, 선형적인 성능향상이 나온다.
- TCP는 congestion으로 인해 goodput이 떨어짐
https://youtu.be/Cxie0FgLogg?t=739
- TCP는 link failure가 생기게 되면 backoff를 시도하고, timeout까지 기다린다.
- timeout이 발생하면 커넥션을 다시생성해야 하므로 오버헤드가 크다.
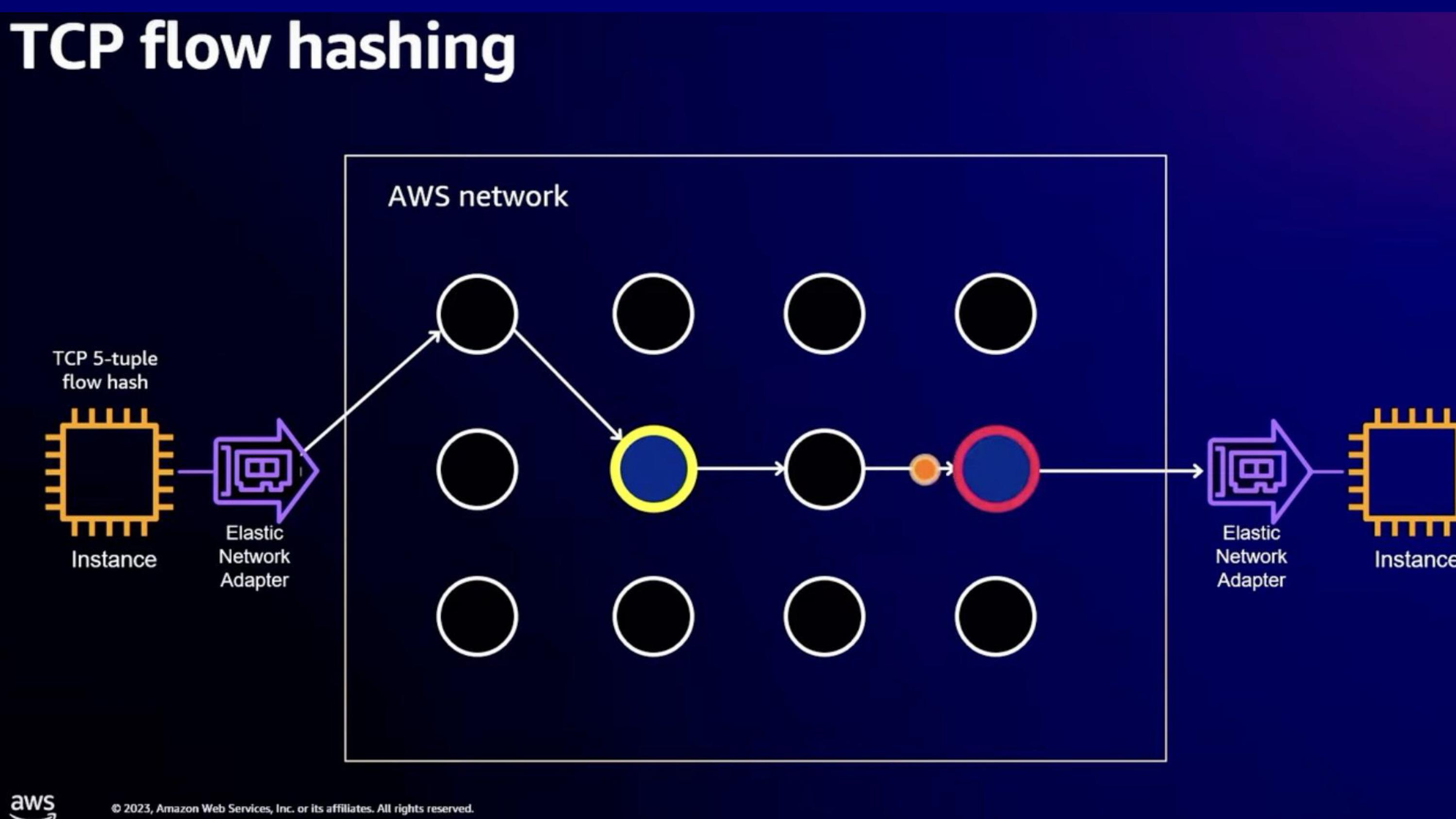
- TCP는 out of order packet을 잘 처리하지 못하기때문에 multipath를 쓰기 힘들다.
https://youtu.be/Cxie0FgLogg?t=739
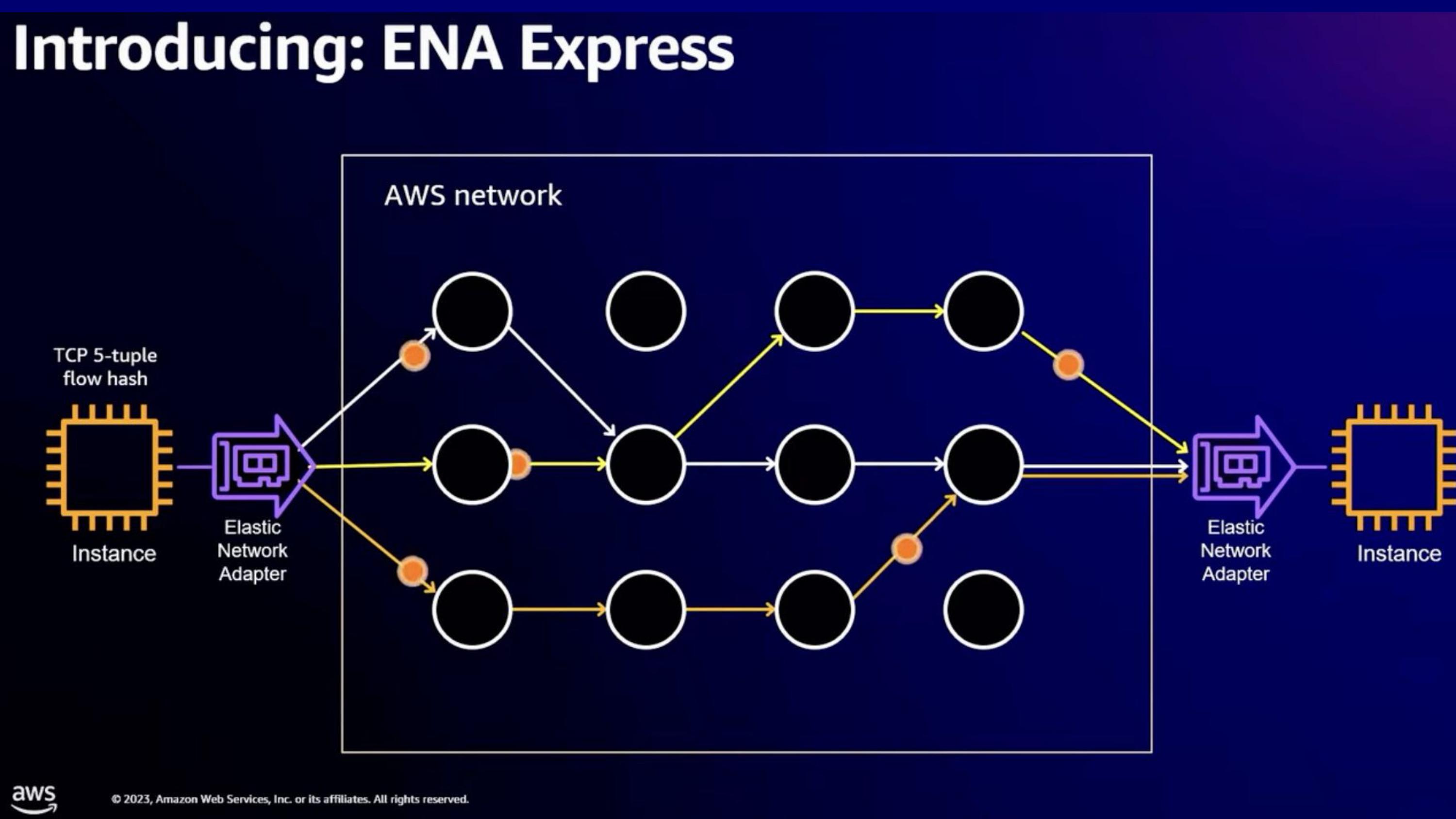
- 하지만 SRD는 여러 경로를 사용하고 backoff 대신 reroute를 하게 됨

A Cloud-Optimized Transport Protocol for Elastic and Scalable HPC
| 패킷 전달 보장 | 패킷 순서 보장 | |
|---|---|---|
| UDP | X | X |
| SRD | O | X |
| TCP | O | O |
- TCP: latency-sesnitve하지않다, lost packet처리가 느림
- RoCE(RDMA over Converged Ethernet) - Infiniband
- priority flow control을 켜야함 - large scale network에선 키면 head-of-line blocking, congestion spreading, deadlock 생길수있음
- multipath loadbalancing
- 모든 경로에 uniform하게 뿌림, hotspot을 피하고 suboptimal path를 찾기위함
- srd를 안쓰는 legacy traffic과 동작할수있어야함 -> RTT를 통해 정보를 수집
- Link failure -> unavailable해지면 network-wide routing update를 기다리지 않고 reroute -> 이게훨씬빠르고 connection re-establish필요없음
- out of order delivery
- reordering: 비싸다, scalability이슈도있음. drop생기면 latency증가, 대부분 패킷은 drop과는 관계없으므로 delay는 불필요함,
- out-of-order packet을 버리면 latency가 증가하고 network bandwidth도 낭비됨
- 그대신 order정보를 윗 레이어에게 전달한다.
- 윗 레이어가 바뀐 message semantic을 맞추어서 사용해야한다
- consgestion control
- incast problem (특정 network device에 패킷이몰려서 buffer가 꽉차는현상)이 receiver network adapter에서 발생하기쉬움
- 모든 경로에서 queueing를 줄여야한다.
- minimum in-flight bytes 를 유지하며 bandwidth를 fair-share 해야함. congestion detection보단 preventing에 초점, in-flight byte limit이 있음
- incoming ack packet의 타이밍 + RTT 변화 + 최근 transmission rate을 기반으로 connection의 현재 transmission rate을 업데이트
- 대부분의 경로에서 RTT가 올라가거나, estimated rate이 낮아지면 congestion으로 판단
EBS

https://youtu.be/Cxie0FgLogg?t=923
EBS도 SRD 활용
Nitro SSD
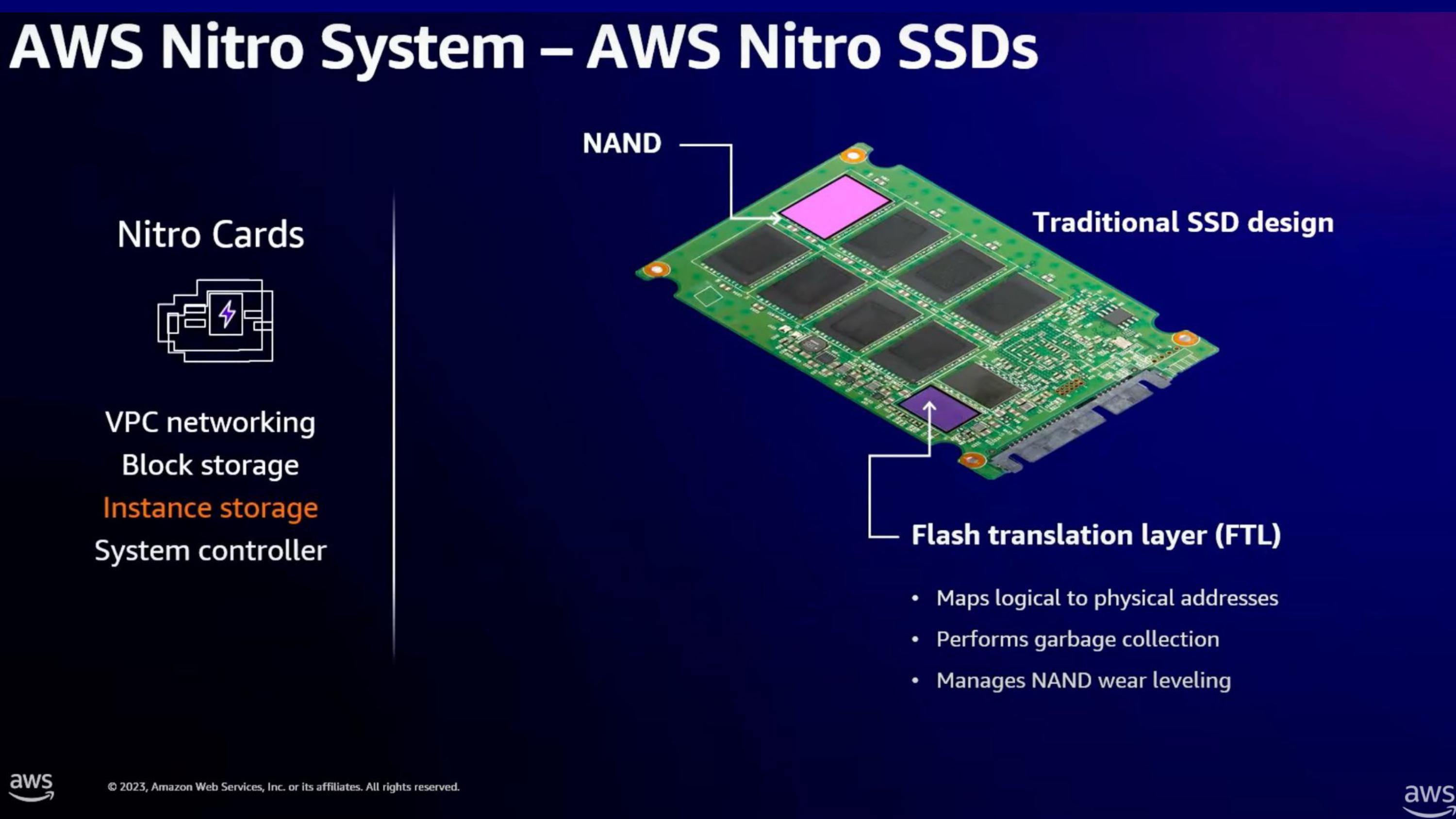
https://youtu.be/Cxie0FgLogg?t=1019
Nitro SSD에 대한 소개 전, SSD의 간단한 내부 구조 (SSD가 주 토픽은 아니니 짧게만 설명합니다)
- SSD는 block단위 erase, page단위 read/write해야하는 NAND의 특징
- 또한 erase로 인한 수명 이슈
- @@@ 좀더 알려줄수있잖아
- 이로 인해 FTL/GC/Wear leveling등의 테크닉이 필요함.
- GC는 request stall을 발생시킨다

- 하지만 여러 SSD를 같이 사용하게되면 예측불가능한 상황들이 많음 (특히 GC)
- heterogeneous도 문제지만 homogeneous도 lifecycle이 다르다
- 이를 해결하기 위해 Nitro card에 FTL을 구현하고, 여러 Nand가 같은 FTL에서 관리되도록 함
Graviton 3 System

https://youtu.be/Cxie0FgLogg?t=1698
- 대부분 서버가 2 socket이지만 얘는 3socket
- graviton3가 저전력이라 rack에 붙은 전력들을 더 사용가능하므로 socket을 추가했다
- (근데 graviton4는 다시 2개다 https://youtu.be/T_hMIjKtSr4?t=1016)
- 각 3개 socket은 baremetal/virtual 상관없이 Nitro card에 의해 독립적인 lifecycle을 가짐
Boot process
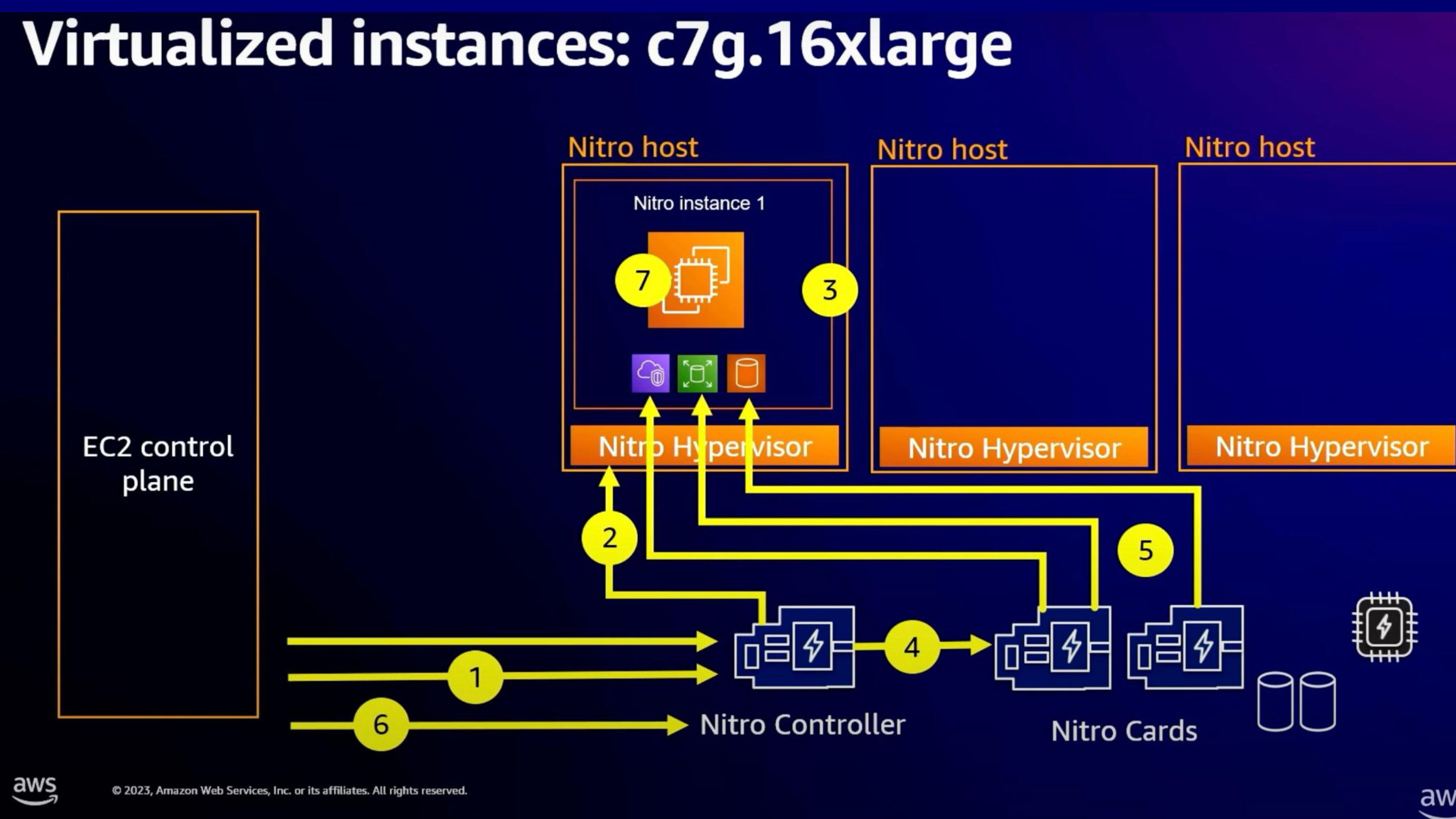
https://youtu.be/Cxie0FgLogg?t=1785
부팅 과정
- Control plane에서 Nitro controller에게 부팅 요청
- Nitro Controller는 Hypervisor에게 요청을 전달
- Hypervisor가 instance resource 할당 (한개 Nitro host에 여러 VM이 들어갈 수 있음)
- 셋업이 완료되면 Nitro card에게 device attach 명령
- Nitro card가 ENA/EBS/Local storage등을 attach함
- 인스턴스 시작 명령
- EBS volume을 보고 boot code 실행
baremetal instance인 경우 부팅하는 주체가 CPU가 아닌 Nitro card가 됨 (Hypervisor가 없으므로)
Mac Instance (Baremetal)

https://youtu.be/Cxie0FgLogg?t=1931
mac instance
- ENA와 EBS는 붙지만 local storage는 없음
- 맥에 내장된 ssd를 아에 안쓰는것일지도
- Nitro card는 PCIe이지만 mac mini엔 PCIe socket이 없으므로 thunderbolt를 통해서 연결
- Nitro controller는 머신 부팅을 위해 부팅스위치와 연결
- 이런 방식으로 다른 baremetal machine들도 연결 가능
References
Hypervisors: Type 1 vs Type 2. [PART 1]
AWS re:Invent 2017: NEW LAUNCH! Amazon EC2 Bare Metal Instances (CMP330)
AWS re:Invent 2017: C5 Instances and the Evolution of Amazon EC2 Virtualization (CMP332)
The Nitro Project: Next-Generation EC2 Infrastructure - AWS Online Tech Talks
AWS re:Invent 2020: Powering next-gen Amazon EC2: Deep dive on the Nitro System
AWS re:Invent 2023 - Deep dive into the AWS Nitro System (CMP306)
AWS re:Invent 2023 - AWS Graviton: The best price performance for your AWS workloads (CMP334)
Take a look inside the lab where AWS makes custom chips
Xen and the art of virtualization (SOSP ‘03) (Slides)
A Cloud-Optimized Transport Protocol for Elastic and Scalable HPC (IEEE Micro ‘20)